

Chunking vs Retrieval: A RAG Case Study on a Real Codebase
Introduction
Most RAG discussions treat chunking and retrieval as separate concerns. Pick a chunk size, pick a retriever, tune k, done. What is less discussed is how much these decisions interact - specifically, how a bad chunking strategy can make retrieval irrelevant before it even runs.
This case study runs the same three questions through four different RAG configurations on the same Python codebase. Semantic RAG with character chunking, semantic RAG with AST-based chunking, lexical RAG with BM25, and hybrid RAG with Reciprocal Rank Fusion. Same LLM. Same codebase. Only the chunking strategy or retrieval method changes.
The finding: chunking strategy mattered more than retrieval strategy. AST-based chunking won or tied on every query. The retrieval method only became decisive after bad chunking had already destroyed the relevant context.
The setup
The target codebase is a small Python task-management application with auth, permissions, billing, notifications, audit logging, and a recurring-task scheduler. Thirteen files. Realistic enough to produce interesting retrieval failures.
Every agent is built the same way: a LangChain agent with a single search_codebase tool, instructed to always search before answering and to cite specific files and functions.
Three questions were chosen to stress different aspects of retrieval:
Q1 tests whether a permission rule documented only in a docstring survives chunking. Q2 tests the lexical gap: the question uses different vocabulary from the code. Q3 tests exact identifier lookup, the easiest case for any retriever.
The four strategies
Script 1: Semantic RAG, character-based chunking RecursiveCharacterTextSplitter at 256 chars / 32 overlap. OpenAI embeddings. Chroma vector store. 173 chunks from 13 files. This is the baseline most RAG tutorials implement.
Script 3: Semantic RAG, AST-based chunking Python's ast module parses each file into a syntax tree. Each top-level class or function becomes one chunk - signature, docstring, and body together. 28 chunks from the same 13 files. Far fewer, far larger, semantically coherent units.
Script 5: Lexical RAG, BM25 Same character-based chunks as Script 1 (173 chunks), retrieved with rank_bm25 instead of embeddings. No vector store. No embedding API calls.
Script 6: Hybrid RAG, Reciprocal Rank Fusion LangChain EnsembleRetriever fusing semantic and BM25 retrievers at equal weights. Same character-based chunks. RRF re-ranks by combining the ranked lists from both retrievers.
Results
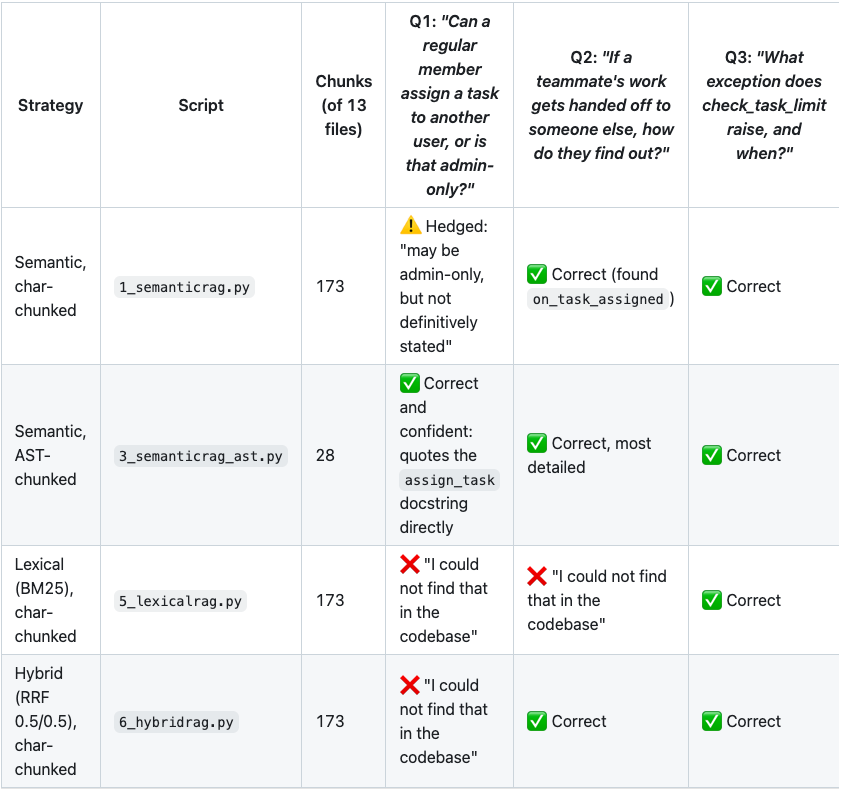
Four RAG strategies, same codebase, same questions - results from the case study
Q1: The docstring question
The answer ("admin only") lives entirely in the docstring of TaskService.assign_task:
def assign_task(self, token: str, task_id: int, assignee_id: int) -> Task:
"""
Reassign a task to another user.
Requires task:assign permission (admin only).
"""
With 256-char chunking, this docstring and the surrounding permission logic are split across multiple character windows, mixed with fragments from main.py seed data and database.py helpers. The embedding retriever returned chunks that mention assignment but never the docstring itself. The agent hedged: "may be admin-only, but not definitively stated."
BM25 and hybrid fared worse. Their top chunks were dominated by unrelated auth.py text, and both returned "I could not find that in the codebase."
With AST-based chunking, the entire TaskService class including that docstring is one chunk. The retriever returns it directly. The agent quotes the docstring verbatim and answers with full confidence.
This is a chunking effect, not a retrieval effect. The retriever in Script 1 was not wrong - it returned the most semantically similar character windows. The relevant information had simply been destroyed by the chunking step before retrieval ran.
Q2: The lexical gap question
"If a teammate's work gets handed off to someone else, how do they find out?"
The code says "assignee" and "on_task_assigned". The question says "teammate" and "handed off". These share almost no tokens.
BM25 matched on "task" and "find" and returned irrelevant auth.py and integrations chunks. It has no way to bridge the gap between "handed off" and "on_task_assigned" without semantic understanding. Result: failed.
Both embedding retrievers found the correct chunk because "hand off work to a teammate" and "assign a task to a user" are close in embedding space even without shared vocabulary. The semantic representation captures the conceptual similarity that lexical matching cannot.
Hybrid RRF also succeeded. Its semantic half compensated for its BM25 half, pulling the correct chunk into the top-k results.
Q3: The exact identifier question
"What exception does check_task_limit raise, and when?"
Every strategy got this right. When the query contains the literal function name from the code, BM25's exact term matching is as effective as embeddings and far cheaper - no embedding API calls required.
This is BM25's strongest use case: exact identifier lookups, error string searches, config key lookups. For these queries, adding a semantic retriever adds cost without adding quality.
Metrics: the precision/recall tradeoff
Script 7 runs a golden set of 6 queries with known-relevant documents against an InMemoryVectorStore at k values of 1, 3, and 5:
| k | Recall | Precision | MRR | nDCG |
|---|---|---|---|---|
| 1 | 0.667 | 0.833 | 0.833 | 0.833 |
| 3 | 0.917 | 0.444 | 0.917 | 1.000 |
| 5 | 1.000 | 0.300 | 0.917 | 0.942 |
Recall climbs toward 1.0 as k grows. Precision falls. This is the expected tradeoff: retrieving more chunks eventually finds every relevant document, but an increasing share of retrieved chunks are irrelevant noise the LLM has to filter out.
The failure at k=3 flags one query whose answer requires synthesising information from two documents. Only one of the two was retrieved. This is a common failure mode in RAG: questions that need multi-document synthesis are harder than questions with a single-document answer.
The decision framework
| Use case | Strategy | Reason |
|---|---|---|
| Conceptual questions about code: permissions, contracts, design intent | AST-based chunking | Keeps function signature, docstring, and body as one retrievable unit |
| Exact identifier / error string / config key lookup | BM25 lexical | Precise, fast, no embedding cost |
| Mixed workload, unpredictable query types | Hybrid RRF | Semantic compensates for lexical gaps; BM25 handles exact matches |
| General prose, documentation, not source code | Semantic, char-chunked | Simple and effective when content lacks syntactic structure worth preserving |
What comes next
The best configuration this case study points to - AST-based chunking combined with hybrid retrieval - was not wired up in this repo. It is the natural next step, and the most likely setup to handle the full range of query types the three test questions represent.
tree-sitter is worth exploring as an alternative to Python's ast module for multi-language codebases. It supports the same unit-based chunking principle with broader language coverage.
A larger golden set would also strengthen the metrics analysis. Six queries is enough to illustrate the precision/recall tradeoff but not enough to draw statistical conclusions about relative strategy performance.
Conclusion
Chunking strategy and retrieval strategy are not independent decisions. Chunking runs first and sets the ceiling for what retrieval can possibly find. A retriever cannot return information that chunking has destroyed.
For code Q&A, AST-based chunking raises that ceiling dramatically. The retrieval method matters most in the middle - once chunking has preserved the relevant context, and once the query's vocabulary diverges from the code's.
The practical order of operations: get chunking right first. Then tune retrieval.
Full source: https://github.com/f2015537/agentic-rag-case-study